


Dopo aver toccato con mano le RX 460 e RX 470 targate SAPPHIRE, non poteva mancare la prova della RX 480 NITRO+ il modello di punta dell’aziende cinese.

La Radeon RX 480 è la miglior incarnazione di Polaris ed è basata sul processo produttivo a 14nm per migliorare l’efficienza energetica, il modello NITRO richiede un connettore aggiuntivo a 8-pin per un TDP di 150w.

Il cuore della RX 480, la GPU Ellesmere ha 2304 Stream Processor, 144 TMU, 32 ROP. Le frequenze della versione da 4GB GDDR5 sono inferiori rispetto allo stesso modello da 8GB GDDR5, nel dettaglio abbiamo una frequenza di 1306 MHz per il core clock e una frequenza di 1759 MHz (7 Gbps effettivi) per le memorie.
Le schede video della famiglia Polaris hanno l’ultima incarnazione dell’architettura Graphics Core Next (GCN), pienamente compatibile con l’l’Async Compute che porta a benefici prestazionali nei videogiochi Vulkan (Open GL) e DirectX 12. Ovviamente vengono supportate le altre tecnologie firmate AMD tra cui FreeSync, TruAudio e LiquidVR.

Il design della nuova SAPPHIRE NITRO+ è estremamente semplice con una costruzione della parte frontale in plastica nera opaca e una texture puntinata. Sulla parte posteriore è presente un backplate mentre sul lato spiccano il logo SAPPHIRE retroilluminato RGB e i due switch per modificare l’illuminazione e cambiare BIOS tra modalità quiet 1,266mhz e “boost” 1,306mhz.

Il dissipatore Dual-X è composto da due due ventole da 95mm con pale migliorate e doppi cuscinetti a sfera che aumentano la silenziosità e durata rispetto ai precedenti modelli. Viene inoltre integrato un sistema di rapida sostituzione o pulizia delle ventole, che permette di rimuovere facilmente ogni singola ventola senza dover smontare altre parti della scheda. Le ventole utilizzano l’Intelligent Fan Control che le disattiva completamente in condizioni di carico leggero per poi attivarle quando la scheda video raggiunge i 52°C.


Come uscite video sono presenti due HDMI 2.0, due DisplayPort 1.4 e un DVI (Dual link). La DisplayPort 1.4 supporta le più recenti e future risoluzioni tra cui: 1080p @240Hz, 1440p @240Hz, 4K @120Hz o perfino 1440p @190Hz “ultrawide”. Inoltre viene supportato l’HDR e codifica/decodifica hardware per la registrazione 4K utilizzando il codec H.265.
| GPU | Radeon RX 480 | Radeon RX 470 |
| Shader Units | 2304 | 2048 |
| ROPs | 32 | 32 |
| Graphics Processor | Ellesmere | Ellesmere |
| Transistors | 5700M | 5700M |
| Memory Size | 4GB/8GB | 4GB/8GB |
| Memory Bus Width | 256 bit | 256 bit |
| Core Clock | up to 1266mhz | up to 1206mhz |
| Memory Clock | 2000mhz | 1650mhz |
[nextpage title=”Analisi Tecnica”]
Con la RX 480 AMD immette sul mercato la prima soluzione basata sui 14 nanometri Samsung / GLOBALFOUNDRIES

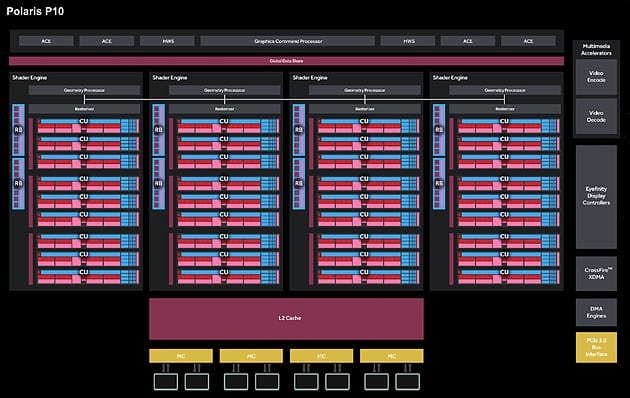
La scheda mantiene tutte le caratteristiche elaborative di Tonga ma le CU sono state portate a (2304 shader) e le TMU passano a 144. Rimane inalterato il rapporto tra ROP e banda, con 32 ROP su un bus di 256bit ma ben più veloce. Le memorie che equipaggia la RX480 sono le potenti ed a bassi timing, samsung K4G80325FB-HC25 8gbps, capaci di 256gb/s di banda passante.

Ogni rasterizzer è composto da 9 CU, separato da un ponte per gli export sulle ROP, ogni raster accede a 8 ROP. Sulla cache sono stati utilizzati molti transistor, il tutto per cercare di rendere migliore la parallelizzazione del flusso dati, ora la cache l2 passa da 768KB a 2MB.
Anche Nvidia ha lavorato molto sul rapporto cache, questa ha bisogno di più cicli di accesso ma può contenere molti più dati da caricare all’istante, per fornire sempre più maggiormente gli shader, vista la potenza teorica di ben 5,9 tera flops. Una potenza matematica e teorica in ALU, capace di eguagliare la GTX 1070 di NVIDIA.
Dentro il Compute Engine
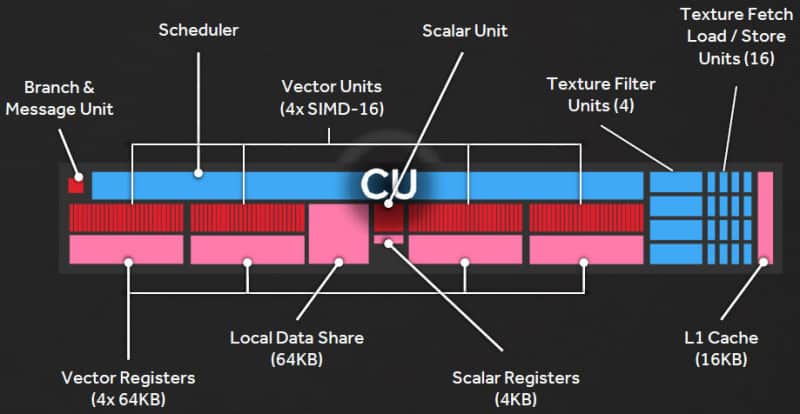
All’interno del compute engine, troviamo lo scheduler che comanda le ALU. Come detto in precedenza, le quattro unità vettoriali, contengono 16 ALU a testa e 256kb di cache per vettore. Internamente possiamo notare i 16 load store, i 16kb di cache l1 e le ben 4 texture unit (TMU), posizionate nello stesso rapporto già visto con Nvidia, ovvero 4 ogni 64 shader o cuda cores.
Schema completo del chip Polaris
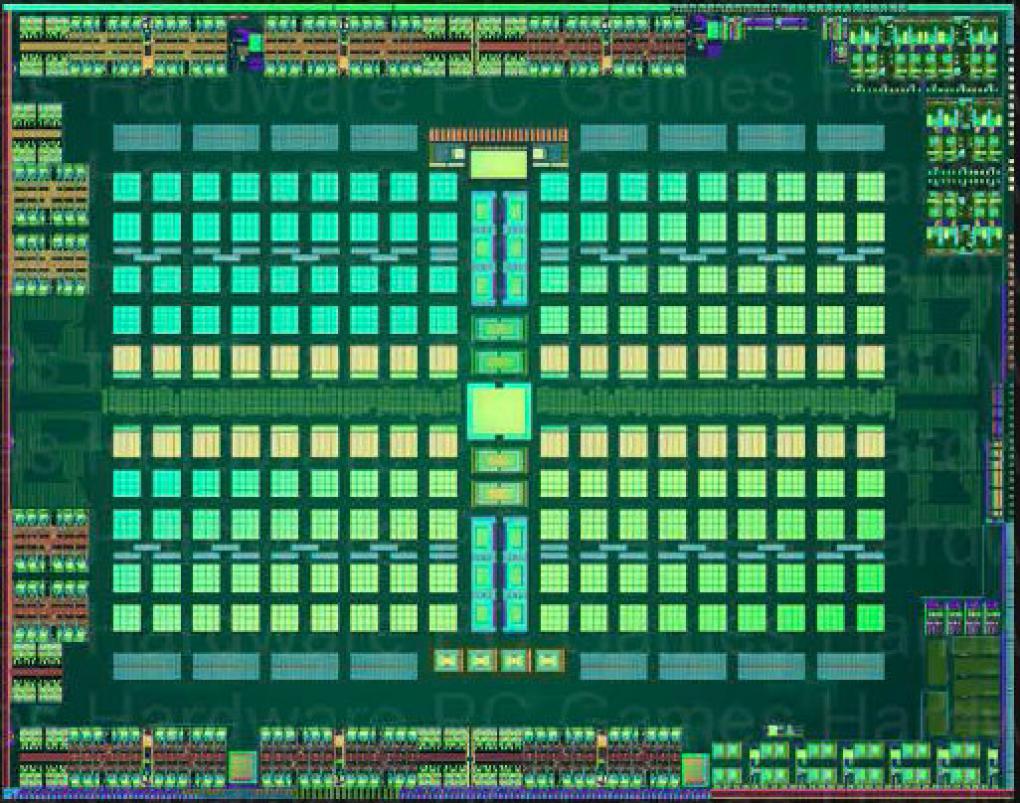
Lo schema è essenzialmente per utenti particolarmente esperti ed attenti, ma possiamo vedere subito, che il chip è del tutto completo, nessun rebrand con più CU, come avvenne per Tonga.
Possiamo vedere dal grafico 36 CU, 4 a rasterizzatore, e le relative TMU affiancate dalla cache l1, disposta sotto le CU e la corposa cache l2 da ben 2mb con 8 partizioni da 256kb..
Memory Compression
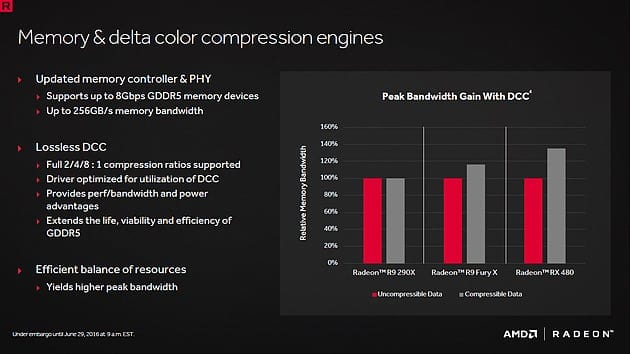
Notevoli le migliorie anche sul fronte memoria, il 40% sbandierato sia da AMD che Nvidia, non produceva i risultati sperati, tanto che spesso si arrivava a soglie del 17-20-25% massimi. Ora Polaris è in grado di decomprimere qualsiasi formato, ed in qualsiasi valore, in scala 8:1 / 4:1 / 2:1. Il valore di 2:1 non veniva compresso, saturando porzioni di banda sequenziali, ora con la nuova modalità si riesce a decomprimere qualsiasi formato, raggiungendo il vero valore teorico impostato sia da Nvidia che da AMD.
La Hawaii 290, pur vantando ben 320gb/s non riusciva ad accedere ad oltre 263gb/s, fattore che la rende più sbilanciata rispetto a Polaris, considerando che tale schede ha il doppio delle ROP senza compressione.
Primitive discard
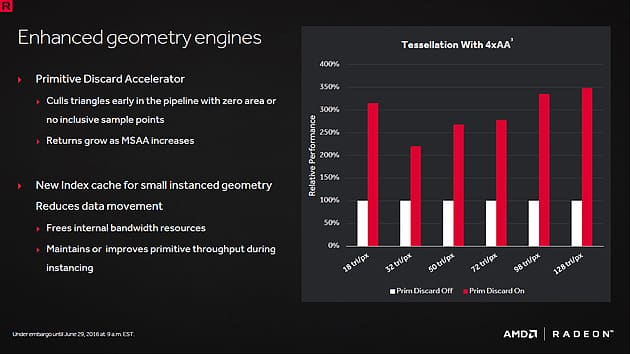
AMD come sottolineato ha una potenza sulle ALU ben sopra alla rivale Nvidia, ma non integra polymorph engine ogni 128 shader come la rivale, si serve sempre dei raster, da cui elabora solo un triangolo su ogni raster, ma la vera difficoltà è data dall’espulsione dei micro triangoli, fattore che spesso nei giochi come The Witcher, basati su un massiccio uso di tassellazione, o sui bench sintetici heaven benchmark (backface culling), facevano crollare la scheda perchè la pipeline grafica si ingolfava di dati, non eliminando a dovere la geometria già calcolata.
Il PDA, compatibile solo con le GPU Polaris o Vega di prossima generazione, fa in modo che la geometria venga espulsa subito, dopo tutte le operazioni sui vertici senza andare ad intasare i buffer. Siamo certi che questo sarà un bel guadagno nei giochi Gameworks Nvidia.
[nextpage title=”Piattaforma e Metodologia di Test”]
Il sistema da test utilizza una versione pulita di Windows 10 appena installata su SSD. Windows, videogiochi e i programmi da benchmark sono aggiornati all’ultima versione.
Dove possibile i benchmark sono svolti almeno due volte.
Tutti i risultati sono registrati con Fraps e I consumi del sistema vengono misurati tramite Wattmetro, OC e temperature gestiti da Radeon WattMan.

Piattaforma
Intel i7 5820K 4.3GHz
Fatal1ty x99 Professional
HyperX Predator 4x4GB DDR4 2400MHz
SSD 850 EVO 500GB
Antec HCP-850w Platinum
Radeon Software Crimson 16.11.3
GeForce 375.86
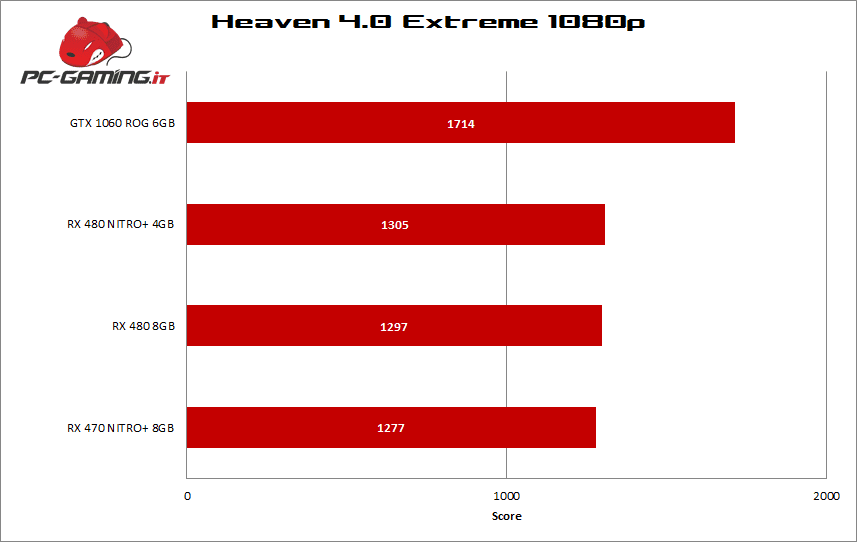
[nextpage title=”3Dmark, Heaven, Valley”]





[nextpage title=”Crysis 3″]


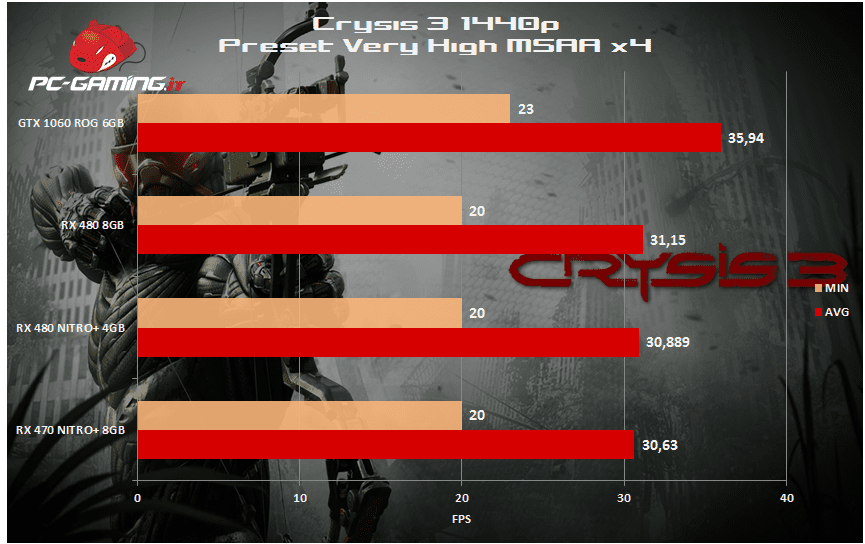
[nextpage title=”La Terra di Mezzo: L’Ombra di Mordor”]
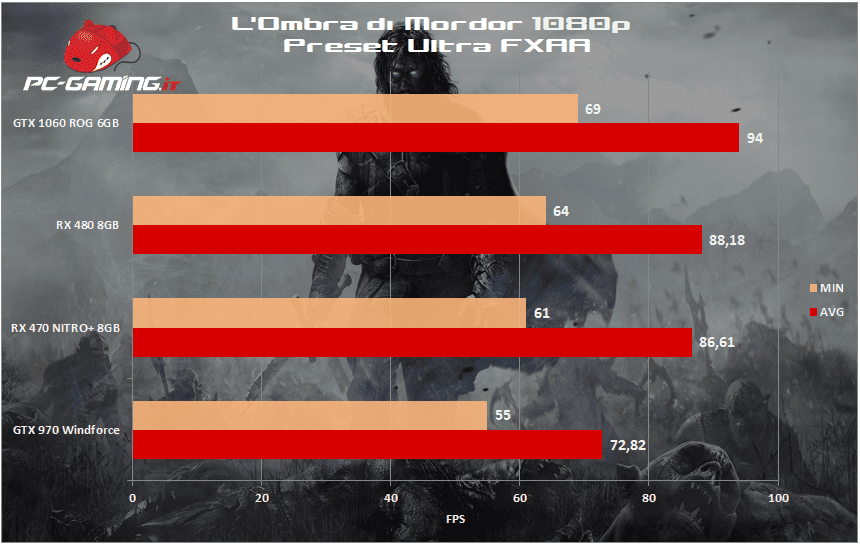
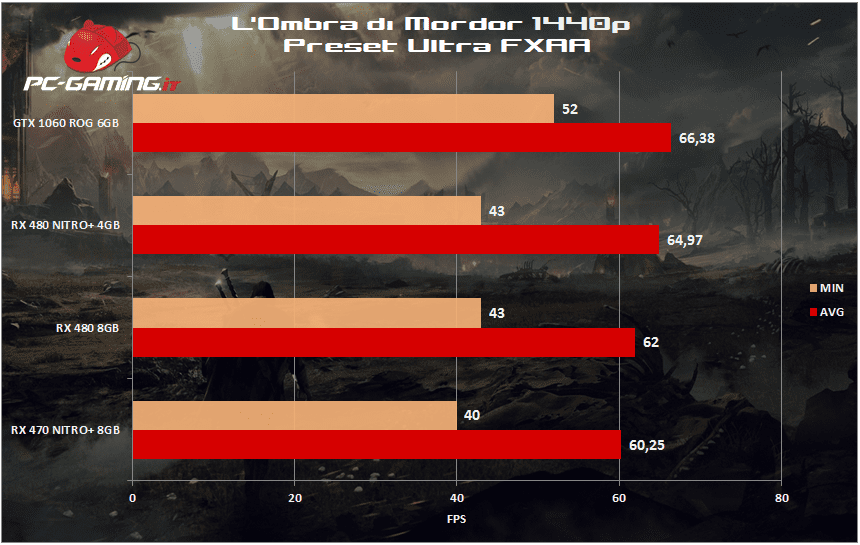
[nextpage title=”Tom Clancy’s The Division”]


[nextpage title=”Rise of the Tomb Raider”]


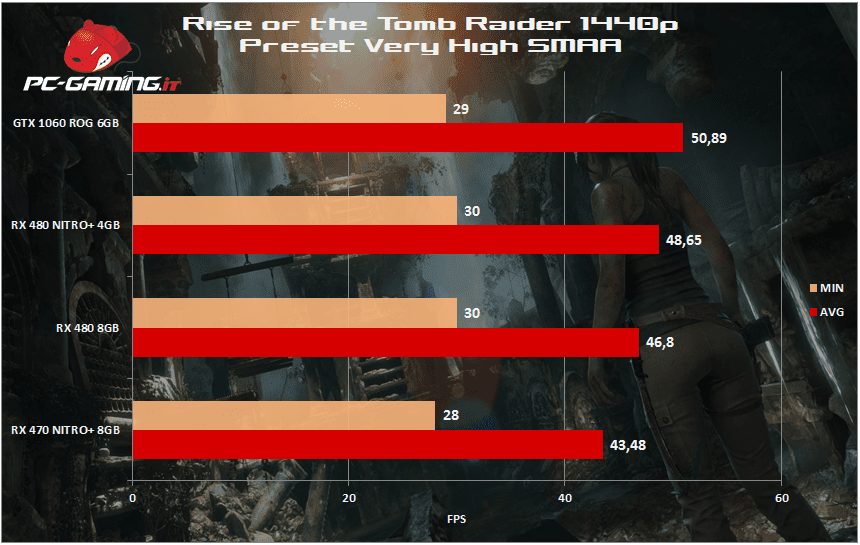
[nextpage title=”The Witcher 3: Wild Hunt”]
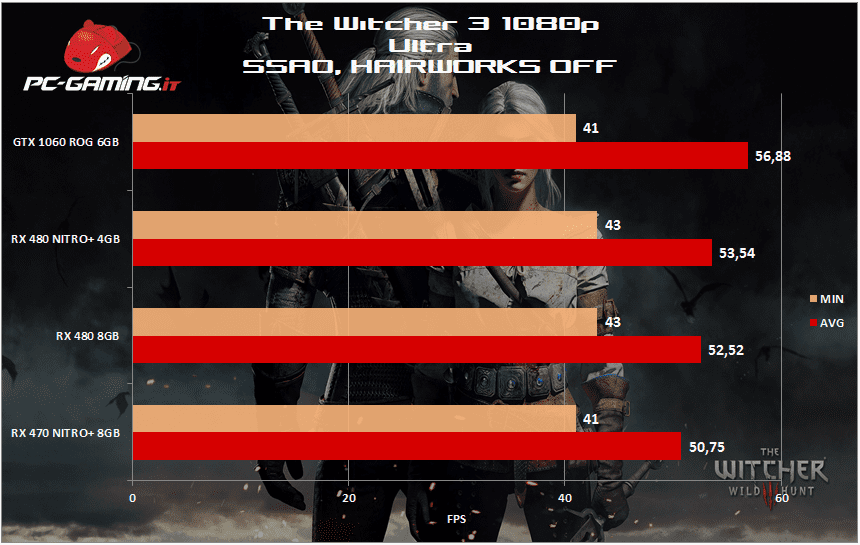
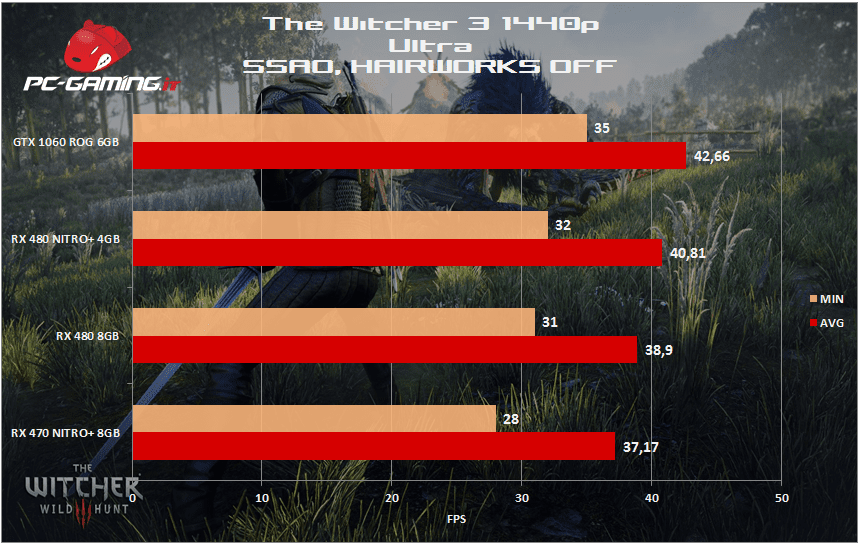
[nextpage title=”Total War: WARHAMMER DX12″]

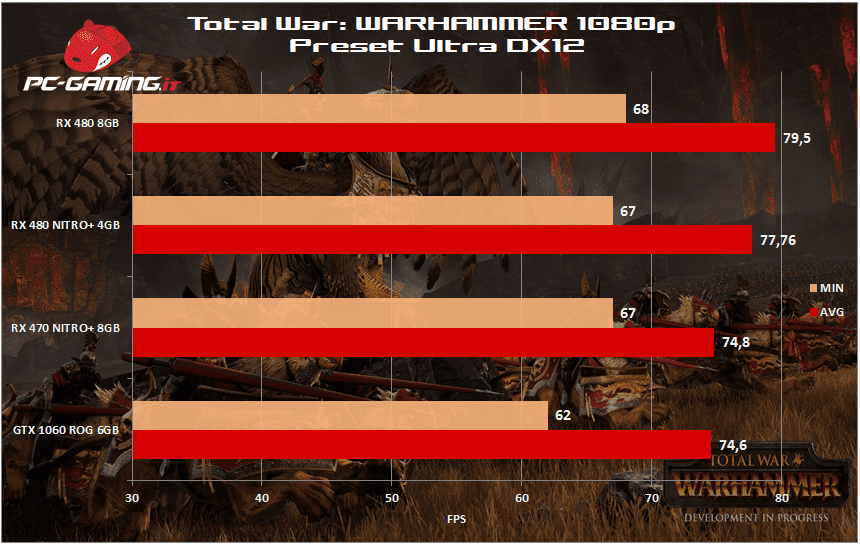
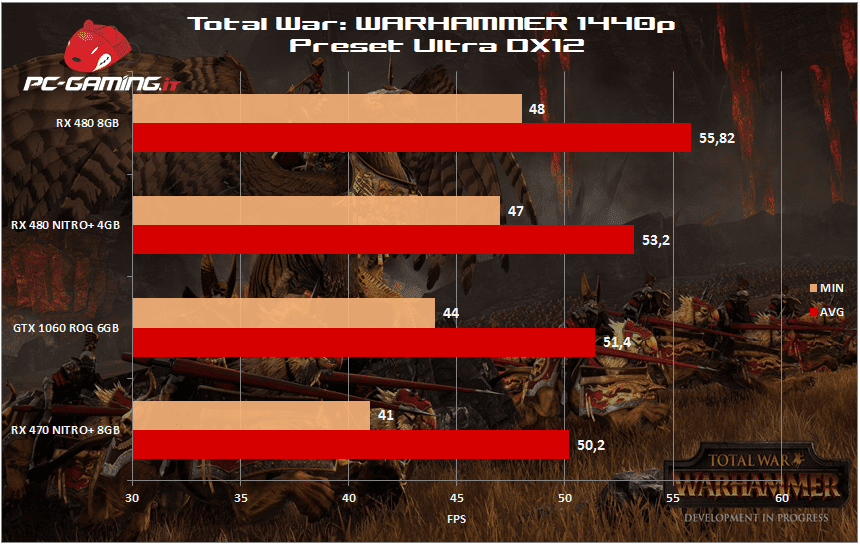
[nextpage title=”Temperature, Consumi”]
Temperature
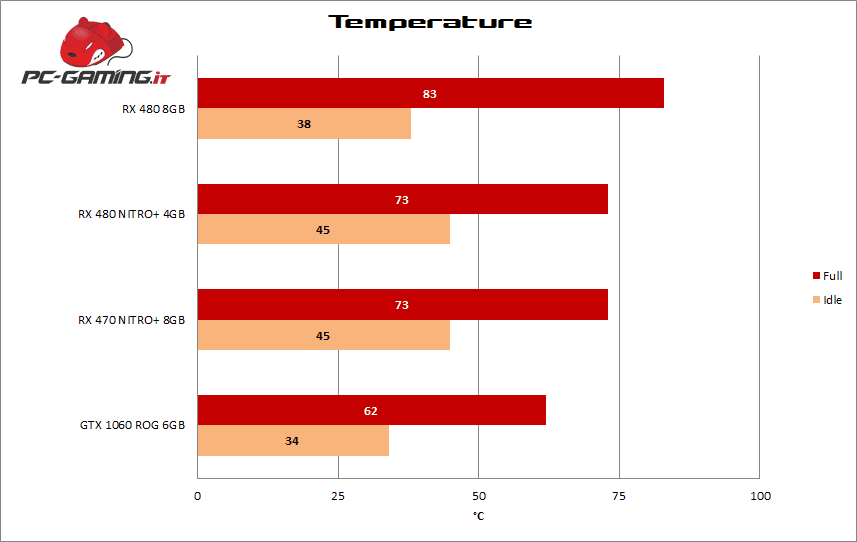
Il nuovo dissipatore Dual-X mantiene in full load una temperatura di 73°C con una discreta silenziosità.
Consumi
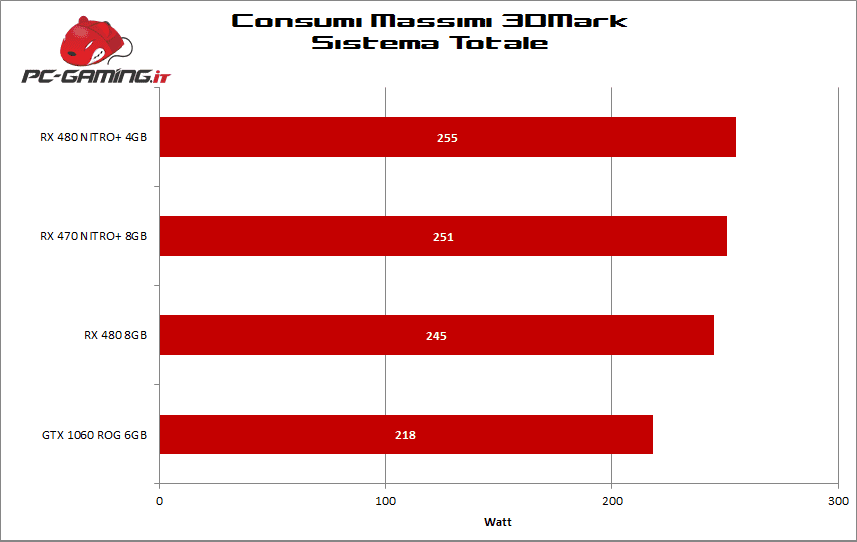
I consumi del modello NITRO+ sono di 255w e sono dovuti all’overlcock di fabbrica.
Overclock
Con le schede video Polaris, l’overclock è gestito tramite il software AMD Wattman che sostituisce CCC Overdriver ed è incluso con la suite AMD Crimson Software. Le GPU SAPPHIRE possono essere controllate anche tramite i l nuovo software ufficiale TriXX3, sviluppato con un design moderno consente di regolare frequenze, voltaggi, gestire l’illuminazione e tutte le altre opzioni fondamentali.

[nextpage title=”Conclusioni”]
La Radeon RX 480 è una scheda video dalle buone prestazioni per chi vuole giocare a 1080p ma anche a 1440p, e di sicuro renderà ancora di più in futuro grazie alla piena compatibilità con le nuove API.
SAPPHIRE con la Radeon RX 480 NITRO+ 4GB ha fatto un ottimo lavoro, offrendo un dissipatore performante di ottima fattura e alcune caratteristiche uniche e ben progettate. Grazie al prezzo estremamente competitivo, per la precisione è il modello più economico sul mercato, diventa un acquisto obbligatorio per tutti i futuri acquirenti di una RX 480 che vogliono risparmiare qualcosa senza tralasciare la qualità.
Questo modello da 4GB rispetto al modello da 8GB ha ovviamente la metà della memoria video, che non crea nessun problema con i videogiochi attuali ma non si ha certezza per il futuro, inoltre le frequenze sono inferiori e la GPU ha “solamente” 5 fasi. A livello pratico le prestazioni sono molto simili ma se avete disponibilità economica il modello Sapphire RX 480 Nitro+ OC da 8GB è la scelta migliore.

















